Look More Than Once
LOMO是百度提出的文本检测深度网络模型,用以解决目前主流模型(如EAST)的感受野对长文本覆盖不足以及对弯曲或波浪形文本检测能力不足的问题。
Look More Than Once: An Accurate Detector for Text of Arbitrary Shapes
1.简介
LOMO(LOok More than Once)网络是百度提出的文本检测深度模型,用以解决目前主流模型(如EAST)的感受野对长文本覆盖不足以及对弯曲或波浪形文本检测能力不足的问题。
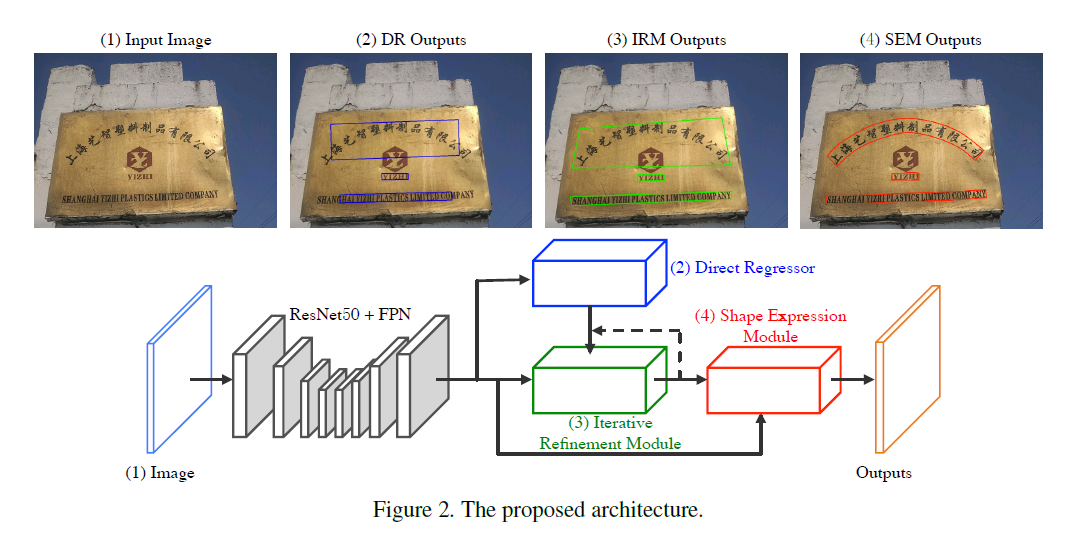
LOMO主要包括三个部分:被称作Derict Regressor的one-shot检测器(DR),以及基于此的IRM(iterative refinement module,迭代细化模块)和SEM(shape expression module形状表达模块)。
通过将IRM和SEM整合起来,LOMO的架构可以实现端到端的训练。本文主要贡献有:提出了一种迭代细化模块用来提高长文本检测的效率;通过一种实例级的形状表达模型用来解决任意形状的文本检测;通过端到端的训练在多个测试集上、多种复杂场景下实现了state-of-the-art的表现。
2.方法介绍
总览
首先用ResNet50+FPN提取特征,将ResNet50的stage-2、stage-3、stage-4、stage-5的特征图合并,得到原图1/4大小、通道数128的特征图,然后采用一个类似于EAST和Deep Regression的Direct Regression网络分支预测单词和文本的像素级quadrangle。
通常,DR分支在检测超长文本的时候效果很差,这也是EAST网络感受野不够大导致的缺陷。因此接下来的IRM分支就是为了解决这个问题而引入的。
IRM分支以DR分支的输出作为输入,不断地对其迭代细化使之逐渐接近GT box的边界。在IRM的帮助下,初步的文本框就能够更加完整的覆盖长文本了。
最后,我们希望能够获得更加tight的文本框表达,尤其是对不规则而文本而言,四边形文本框很容易包含更多的背景图案。SEM模块能学习到文本行地文本区域、中心线、边界坐标偏移等属性,从而更加紧凑地表达各种不规则文本框。
Direct Regression
从EAST网络获得的启发,本文也采用全卷积子网络用来做DR。基于前面提取的特征图,采用了一个密集的文本/非文本通道来做像素级的文本预测。和EAST类似,在做文本区域预测的时候也采用了shrunk方法,每一个被包含在原始区域的shrunk GT box里面的像素被认为是一个正样本。每个正样本像素有八个通道,分别用来预测该像素点相对于四个角的偏移量。因此,DR分支的loss函数包括两个部分:文本/非文本分类项和位置回归项。
我们将文本/非文本分类检测看作一个在1/4尺度特征图上的二分类任务。相对于EAST网络采用的Dice loss,我们提出了另外一种在感受野尺寸下尺度不变的用来提高DR尺度泛化能力的损失函数。L_cls定义如下:
- L_cls = 1 - 2 * sum(y · y_hat · w) / (sum(y · w) + sum(y_hat · w))(1)
其中,y是0/1 label map,y_hat是预测的score map,sum是2D空间的累积函数。另外,W也是2D的weight map,在weight map w中,所有位置可以分为positive和negative两种,其中positive的位置上的值通过正则化常数l(实验中l=64)除以该点对应的四边形的最短边得到,negative处的值直接设置为1.0。
另外,本文采用smooth L1损失函数优化location回归项L_loc。
结合两者,得到L_dr的损失函数定义:
- L_dr = λ * L_cls + L_loc (2)
其中超参数λ在我们的实验中被设置为0.01
迭代细化模块(Iterative Refinement Module)
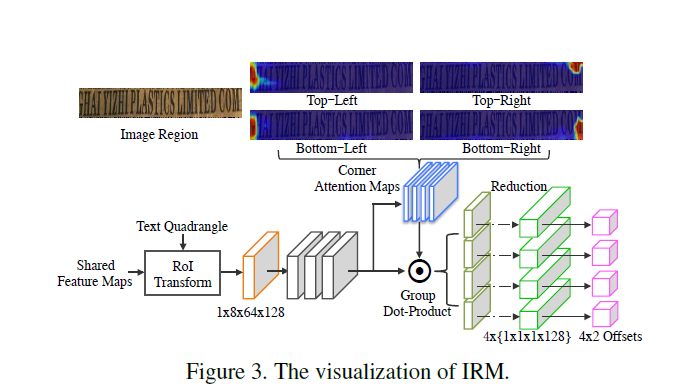
IRM模块的设计思想来自于Faster R-CNN,但是只使用了其bonding box回归的部分,并且使用RoI transform层来从输入的text quadrangel中提取特征块,而非RoI pooling或者RoI align等方法。和后面两者比起来,RoI transform能够在保持纵横比不变的情况下抽取到四边形的特征块。另外,在同样的感受野的情况下,越接近角点的位置,越能感知到更精确的边界信息。因此,一个角点注意力机制被引入到本文的模型中用来回归角点的坐标偏移。
对于每一个text quadrangel,我们将共享特征图feed到RoI transform layer,然后得到一个1x8x64x128的特征块。然后用3x3的卷积去抽取丰富的信息,我们把这一层称作f_r。然后将其输入进一个1x1的卷积层、一个sigmoid层,来学习四个corner attention map,称为 m_a,使用corner attention map的值来作为的corner偏移回归的权重。联合f_r和m_a,输入到reduce_sum中就可以得到4个角点的回归特征。
-
f_c_i = reduce_sum(f_r · m_a_i, axis = [1, 2]) i = 1,2,3,4 (3)
其中,f_c_i代表第i个角点回归特征,shape是1x1x1x128。m_a_i是第i个学习到的corner attention map。最后,4个header被用于预测基于角点回归特征f_c的输入四边形和gt四边形之间的4个角点的偏移。
在训练阶段,我们定义最初从DR探测到的K个四边形以及其角点回归的损失计算如下:
- L_irm = 1 / (K * 8) Σ(k=1_8)Σ(j=1_8)smooth_L1(c_k_j, c_hat_k_j)
c_k_j代表第K对探测到的四边形(这是指EAST网络输出的score map对应的四边形文本框,本文中叫做Direct Regression branch,其和shared feature maps一起作为RoI Transform的输入)和gt四边形之间的第j个坐标偏移(因为有四个角点所以有8个坐标),C_hat_k_j是对应的预测值。该loss对于corner attention map的极强的响应为各自的角点回归提供了极高的支撑。并且,如果IRM在测试期间可以持续的带来优化,那么它可以被执行一到多次。
形状表达模块(Shape Expression Module)
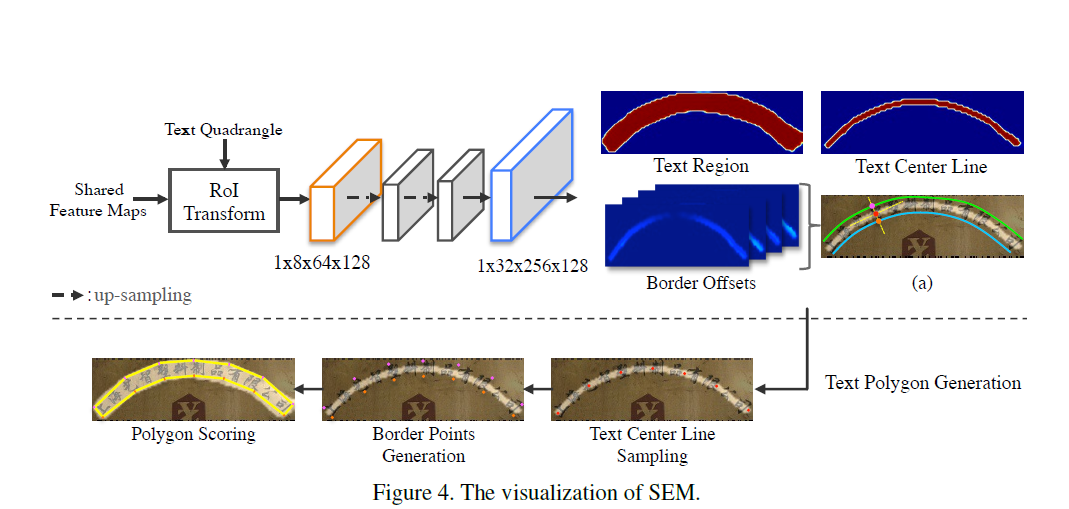 四边形的文本表达不能够精确地描述不规则形状,尤其是弧形或者波浪形文本。受 Mask R-CNN 启发,本文提出了一种基于候选框的形状表达模块SEM。SEM是一个紧随在RoI transform层之后的全卷积网络,通过回归几何图形的文本区域、文本中心线和边缘偏移这三种性质来构造精确的文本实例表达。
四边形的文本表达不能够精确地描述不规则形状,尤其是弧形或者波浪形文本。受 Mask R-CNN 启发,本文提出了一种基于候选框的形状表达模块SEM。SEM是一个紧随在RoI transform层之后的全卷积网络,通过回归几何图形的文本区域、文本中心线和边缘偏移这三种性质来构造精确的文本实例表达。
文本区域(text region)是一种 binary mask,前景像素被置为1,后景像素被置为0。文本中心线(text center line)也是一个binary mask,但是是基于标注四边形的side-shrunk版本来做的。边缘偏移(border offsets)是4通道的map,其值在对应的文本中心线map的位置处的正响应的合法值(注:Border offsets are 4 channel maps, which have valid values within the area of positive response on the corresponding location of the text line map..==不知道该怎么翻译比较好==)
如图4(a)所示,我们画一条垂直于该中心线的法线,得到该法线与上边缘和下边缘的两个交点(border points,粉色和橘色的点),对于每个红色的点,通过计算它到上下两个border points的距离可以得到四个border offsets。
SEM的结构如图4所示,RoI transform层抽取特征后,输出到两个卷积stage(每个stage包含一个上采样和一个3x3的卷积),然后用一个1x1的6通道的卷积来回归所有的text property maps。SEM的目标函数如下:
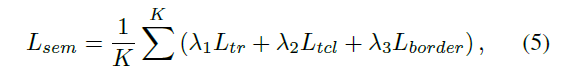 K代表IRM输出的四边形的个数,L_tr和L_tcl分别是文本区域和文本线的dice-coefficient损失,L_border通过smooth L1平滑损失计算得到。权重λ1、λ2、λ3分别设置为0.01、0.01和1.0。
K代表IRM输出的四边形的个数,L_tr和L_tcl分别是文本区域和文本线的dice-coefficient损失,L_border通过smooth L1平滑损失计算得到。权重λ1、λ2、λ3分别设置为0.01、0.01和1.0。
文本多边形生成
我们提出了一种弹性的文本多边形生成策略来构建任意形状的文本实例描述。
策略包含三个步骤:
- 文本中心线采样
- border points生成
- 多边形scoring
首先,在文本中心线采样的步骤中,我们在预测的文本中心线map上从左到右采样n个等距的点。根据SCUTCTW1500的定义,我们在应用到弯曲的文本检测时将n设置为7,在应用到四边形标注的数据集时将n设置为2(可以降低模型复杂度)。然后就可以通过采样到的中心线的点,以及在同一位置处的四个边界偏移maps来决定对应的边界点。通过顺时针的连接所有的边界点,我们就能得到一个复杂的多边形表达。最后,用多边形文本区域响应的平均值来计算新的confidence score。
训练和inference
总的loss计算如下:
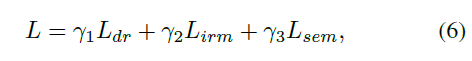 上面的λ全部设为1就好。
上面的λ全部设为1就好。
训练分为两步。
在warming-up step,首先用合成的数据对DR分支训练10个epoch,此时DR分支能对真实数据生成能够覆盖绝大多数文本实例的较高召回率的候选框。
在fine-tune step,我们在真实的数据集上微调三个分支,再训练10个epoch。IRM和SEM都使用DR分支生成的候选框。非极大值抑制用来获取最高的K个候选框。但是由于DR分支一开始的表现会很差,所以我们在这K个候选框中随机选取一半,再用随机选取一半的GT来凑数。PS,IRM在训练的时候只执行一次。
在inference阶段,首先由DR生成四边形的score map和geometry map,然后由NMS生成初步的候选框。接着候选框和shared特征图都被输入到IRM中进行多重优化。优化后的四边形又和特征图一起被送到SEM生成精确的文本多边形和confidence scores。最后,用一个阈值s来过滤置信度较低的文本框。实验中s=0.1。